March 5, 2026 · Experiment
Research: Spatial Constraint Satisfaction Does Not Scale In Auto-Regressive Models
What we did:
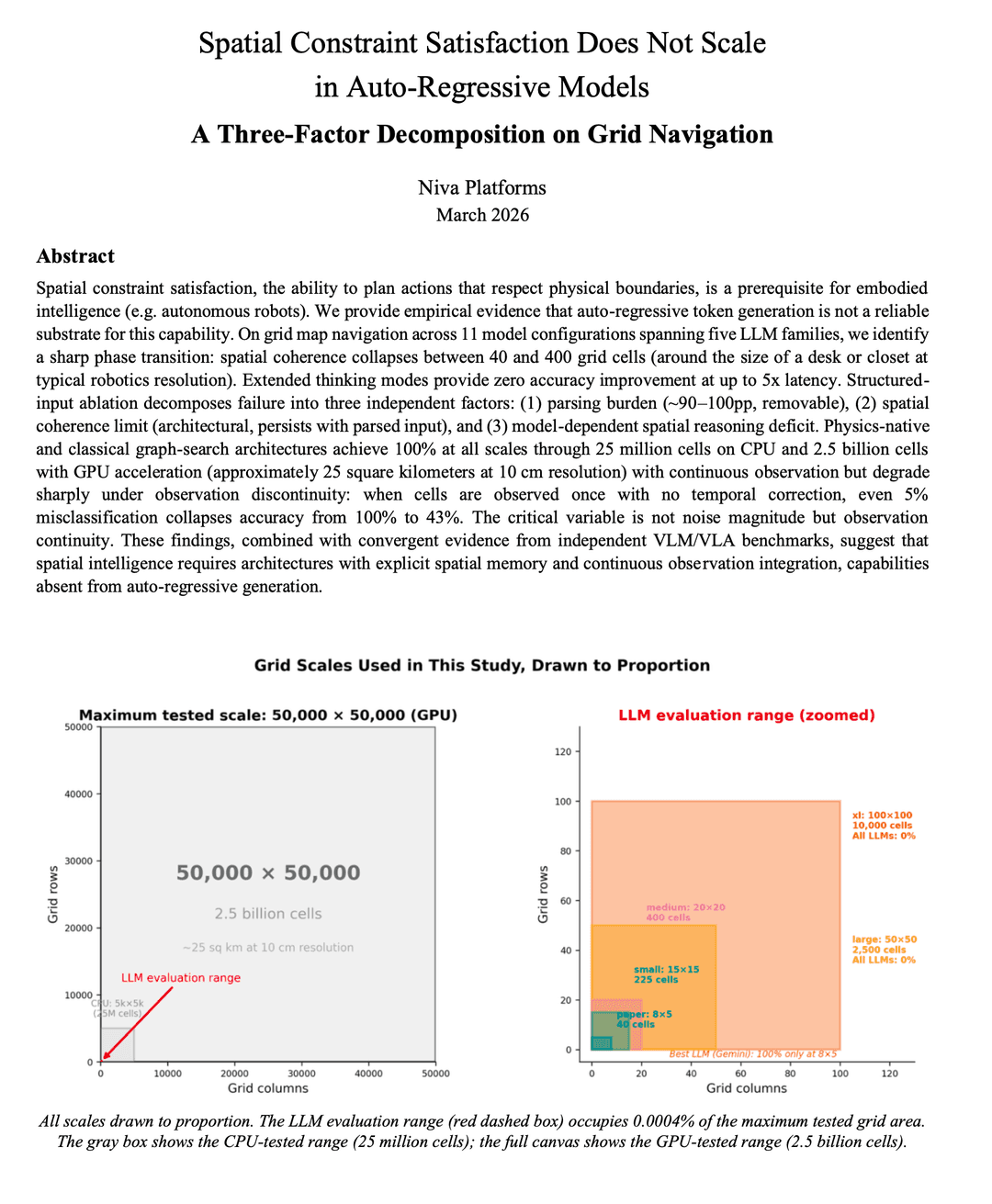
To find the limits of spatial intelligence for robotics and why they easily fail, we extended Han et al.'s ASCII grid map navigation study (arXiv:2601.05529) from 8×5 grids (40 cells - size of a desk) to a 50,000×50,000 grid (2.5 billion cells - 25 sq km at 10cm resolution), tested 11 frontier LLM variants across 5 major models on their ability to navigate the maps, and ran a structured-input ablation to isolate why LLMs fail at spatial constraint satisfaction (navigation).
Headline numbers:
- Physics-native and classical graph-search architectures achieve 100% success at every scale tested, from 40 cells to 2.5 billion cells on a single consumer GPU
- The best LLM (Gemini 3.0 Pro) achieves 100% only at 8×5 (size of a desk) and collapses to 0% by 20×20 (size of a bathroom). Claude 4.5 and GPT-5.2 score 0% at every scale
- When we removed the parsing burden by giving LLMs structured coordinate input, Gemini and GPT-5.2 recovered to 100% at minor scales but still collapsed by 50×50 grids (2.5K cells). Claude 4.5 Sonnet remained at 0% regardless of input format
- Extended thinking modes (GPT-5.2 low/medium/high) produced zero accuracy improvement at up to 5x latency
Why it matters:
Embodied AI (i.e., robots) need spatial understanding, but most robotic AI systems are build on LLMs (or LLMs + Vision like VLA’s) but perform poorly in real world scenarios. Our study finds that LLM spatial failure decomposes into three independent factors: parsing burden, spatial coherence limit, and model-dependent reasoning deficit. This is a diagnostic framework applicable to any model, including VLMs and VLAs that share the same auto-regressive backbone.
The coherence limit is not a training problem. It is a phase transition: sharp, universal across model families, and unresponsive to reasoning amplification. More thinking tokens make the problem worse, not better. Physics-native planning is immune to all three LLM failure modes.
Bottom line: LLMs cannot do spatial constraint satisfaction at the scale of a small office, even with pre-parsed input and extended reasoning. Classical graph search and Manifold's physics-native architecture solve the same problem across 25 square kilometers on commodity hardware with 100% accuracy. The question is not how to fix LLMs for spatial reasoning, but why you would try when deterministic alternatives exist that also handle heterogeneous terrain, physical uncertainty, and continuous sensor integration.